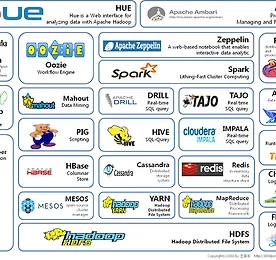
 [HADOOP] Eco System
[HADOOP] ECO SYSTEM Eco System은 원래 생물학용어이다. 자연환경과 생물이 서로 영향을 주고 받으며 함께 생존하는 자연계 질서를 일컫는다. 1993년 미국 하버드대학교 연구교수인 제임스무어가 이러한 뜻을 비즈니스에 접목시켜 '비즈니스 에코시스템'이라는 용어를 탄생시켰고, 주로 IT 분야 여러 기업이 리더를 중심으로 협력하고 함께 발전하는 것을 지칭한다. [출처 : http://1004jonghee.tistory.com/127] 분야 솔루션 NoSQL HBase, Cassandra, MongoDB, CouchDB, Couchbase, Cloudata, Riak, Neo4j Cache Redis, Memcached RPC Thrift, Avro, Protocol Buffer Collec..
더보기
[HADOOP] Eco System
[HADOOP] ECO SYSTEM Eco System은 원래 생물학용어이다. 자연환경과 생물이 서로 영향을 주고 받으며 함께 생존하는 자연계 질서를 일컫는다. 1993년 미국 하버드대학교 연구교수인 제임스무어가 이러한 뜻을 비즈니스에 접목시켜 '비즈니스 에코시스템'이라는 용어를 탄생시켰고, 주로 IT 분야 여러 기업이 리더를 중심으로 협력하고 함께 발전하는 것을 지칭한다. [출처 : http://1004jonghee.tistory.com/127] 분야 솔루션 NoSQL HBase, Cassandra, MongoDB, CouchDB, Couchbase, Cloudata, Riak, Neo4j Cache Redis, Memcached RPC Thrift, Avro, Protocol Buffer Collec..
더보기
[HADOOP] 빅데이터 저장과 처리 및 데이터의 분류
HADOOP 빅데이터 저장과 처리 각자의 생각과 개념은 차이가 있지만 빅데이터를 어떻게 저장하는지는 HDFS(Hadoop Distribured File System) 빅데이터를 어떻게 처리(연산)하는지는 MapReduce 라고 생각하면 된다. HDFS는 신뢰할 수 있는 공유 스토리지 MapReduce는 분산 컴퓨팅이라고 보면 된다. 데이터는 크게 세 가지로 분류된다 정형 데이터 - 정규화를 만족하는 데이터로 기간, 관리, 정보, 분석, 업무의 데이터 반정형 데이터 - 웹, 보안, 로그, 센서 데이터 비정형 데이터 - 문자, 동영상, 이미지, 위치정보 등의 데이터
더보기


